OJ10:张量相乘的最小开销问题 ¶
about 1993 words 75 lines of code 5 images reading time 11 minutes
Description¶
张量(tensor)乘法和广播(broadcasting)是一种在张量之间进行运算的方法,它可以用来表示一些复杂的数学和物理问题,例如神经网络,图像处理,信号处理等。为了理解张量乘法和广播,我们首先需要了解什么是张量,以及它的形状和维度。
张量(tensor)是一种可以表示多维数组的数据结构,它可以有任意的维度和形状。维度(dimension)是张量的层次,表示张量有多少个方向或轴(axis
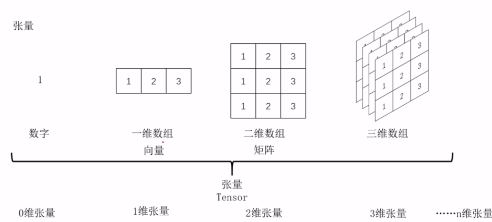
其中 0 维张量可用一个可表示为标量,1 维张量可表示为向量,2 维张量可表示为矩阵,更高维的张量可视为由低维张量作为元素构成的向量、矩阵等:
如 3 维张量可表示为:
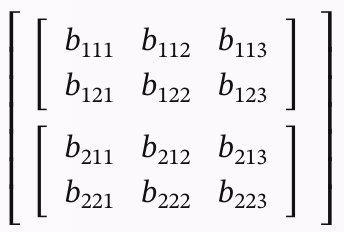
在张量之间进行运算时,我们需要考虑它们的形状是否匹配,以及是否需要进行广播(broadcasting
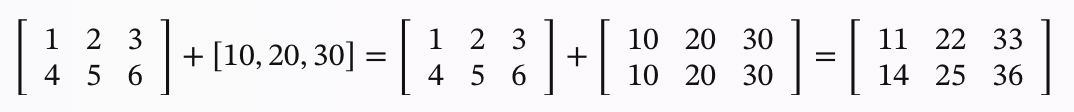
更具体而言,广播(broadcasting)是一种在支持张量的框架中,如 Numpy[1] 和 Pytorch[2] ,为了应对形状不同但满足某些特定条件(下一段具体说明)的张量进行运算所执行的操作。广播的目的是将两个不同形状的张量变成两个形状相同的张量,即先对小的张量添加轴(使其维度与较大的张量相同
广播的原则是:如果两个张量的后缘维度(trailing dimension,即从末尾开始算起的维度)的轴长度相符,或其中的一方的长度为 1,则认为它们是广播兼容的。广播会在缺失和(或)长度为 1 的维度上进行。例如,一个形状为(3,2,2,2)的 4 维张量 A 和一个形状为(1,1,2,2)的 4 维张量 B 是广播兼容的,它们相乘的过程如下所示,先将 B 在第一维方向上复制 3 份,第二维方向上复制 2 份,这样它的形状和 A 相同,之后进行逐元素乘。
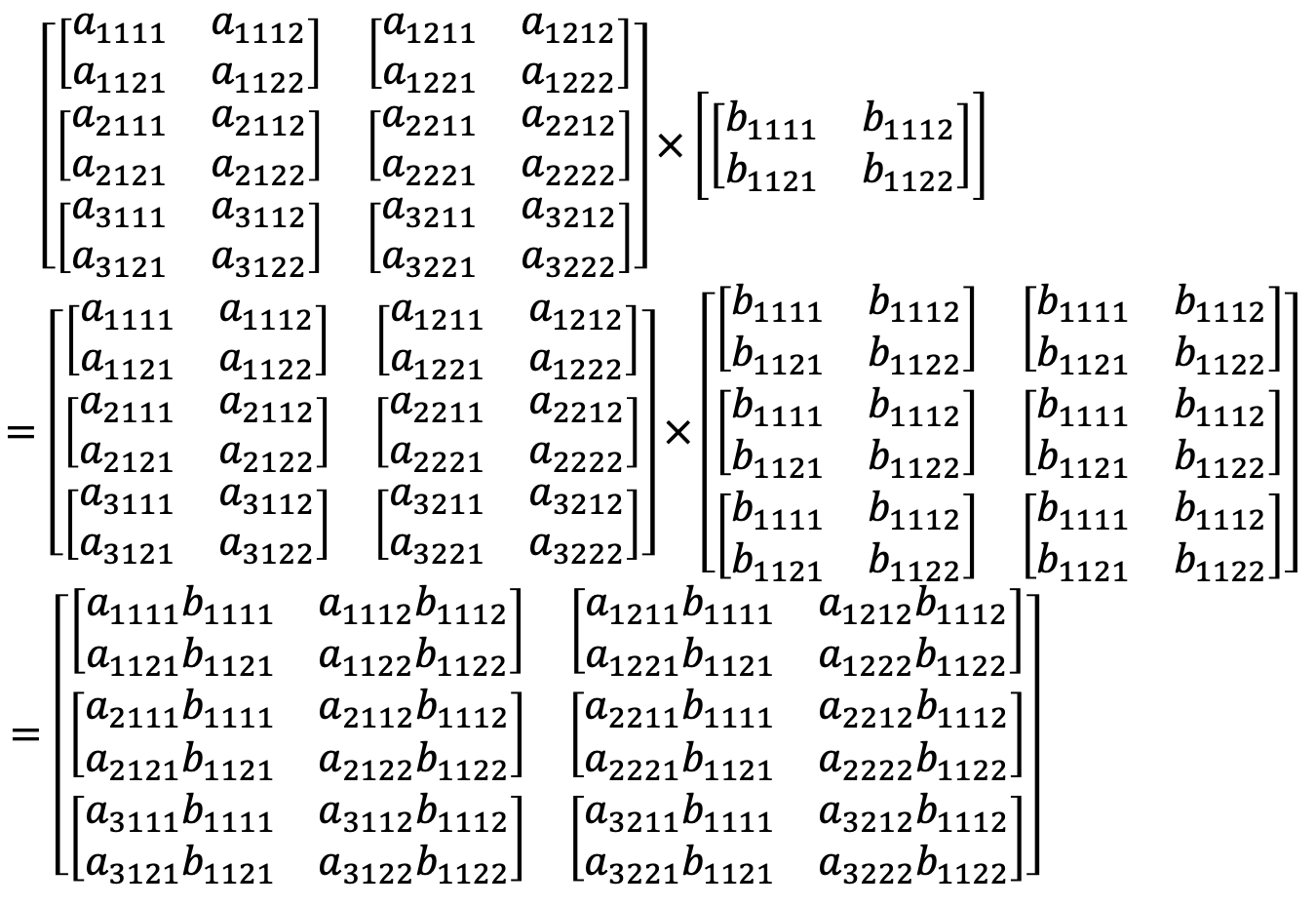
结合上述张量乘法和广播机制,以及标准的线性代数中的矩阵乘法,我们考虑如下的运算:计算 X1 X2 ... * Xn,每个 Xi 代表一个 K 维张量。有以下说明:
(1)它们的维度数 K 一样,且大于等于 2。例如都是三维张量或都是四维张量。
(2)将每一个 K 维张量看成由矩阵(2 维张量) 作为元素构成的 K-2 维张量。前 K-2 维按照上述的张量乘法和广播进行运算,最后 2 维按照标准矩阵乘法进行运算。例如
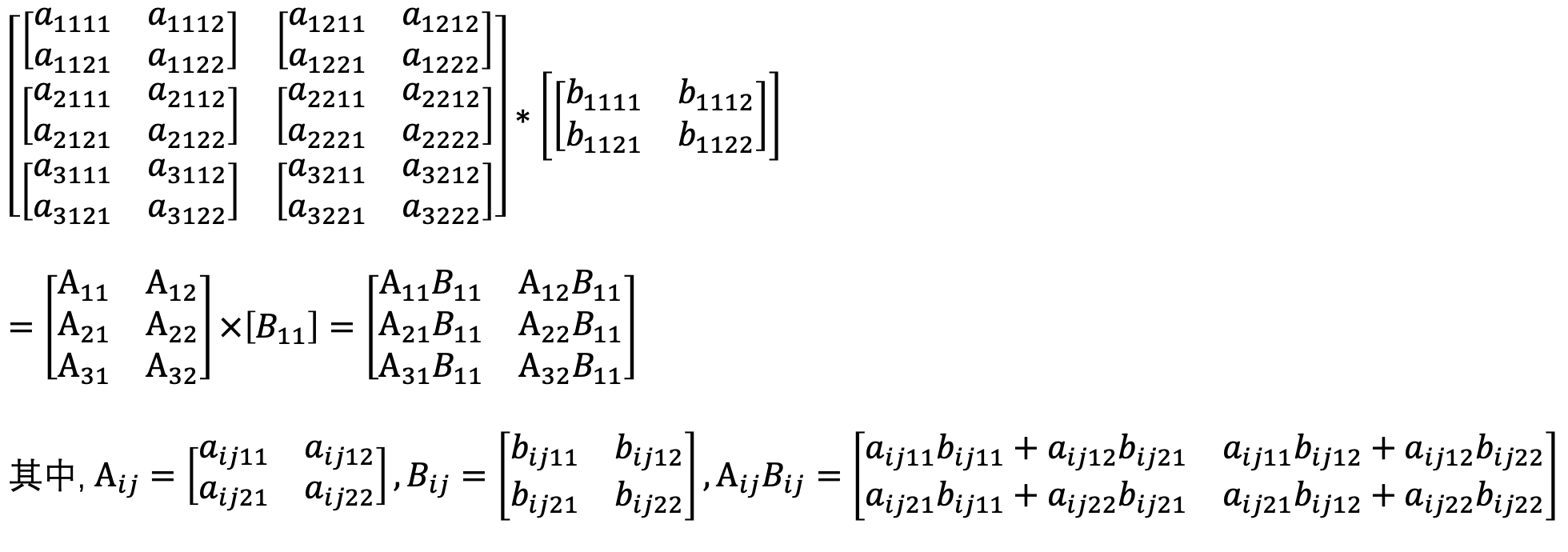
(3)为满足最后两维按照标准矩阵乘法,相邻两个张量的后两维必须满足矩阵乘法的要求,即 X(i) 的最后一维大小必须等于 X(i+1) 的倒数第二维大小。
(4)为满足张量乘法和广播机制的要求,对前 K-2 维中任意第 k 维,任何张量 Xi 在该维度的大小只能是两个取值中的一个:1 或 Dk。Dk 为一大于 1 的正整数,对于不同维度 k,k',对应的 Dk,Dk' 可不同。前 K-2 维中按照可广播的逐元素乘。即相邻两个张量 Xi,X(i+1) 相乘时,对于任意维度 k: 1≤k≤K-2,如果 Xi 第 k 维大小等于 X(i+1) 第 k 维大小 , 则在该维度上逐元素相乘;如果 Xi 第 k 维大小不等于 X(i+1) 第 k 维大小,即其中一个等于 1,另一个等于 Dk,则进行广播并逐元素乘(将该维度等于 1 的张量在该维度上复制 Dk 份后,与另一张量在该维度上逐元素乘
(5)定义计算开销为需要进行的标量乘法的次数。求给定 n 个张量依次相乘的计算开销最小的“完全括号”方案(结合律顺序)的开销。
求:计算开销最小的“完全括号”方案(结合律顺序)的开销。
参考资料:
更多参考资料:
https://zhuanlan.zhihu.com/p/499189580
https://pytorch.org/docs/stable/generated/torch.bmm.html
例子 :
三个三维张量 \(X1*X2*X3\) ,维度大小为: \(X1=[1,1,2], X2=[1,2,3], X3=[10,3,4]\) , 共有两种方案:
方案 1:\((X1 *X2)* X3\) , 计算复杂度 = \(1 *(1* 2 *3)+10* (1 *3* 4)=126\)
方案 2:\(X1 *(X2* X3)\), = \(10 *(2* 3 *4)+10* (1 *2* 4)=320\)
方案 1 优于方案 2,应输出 126。
Input¶
第一行输入两个整数 n,K,代表共有 n 个张量相乘,每个张量都是 K 维。接下来 n 行中,每行代表一个张量,有 K 个由空格分隔的整数,第 k 个整数代表该张量第 k 维的大小。
Output¶
计算输入的 n 个张量依次相乘的计算开销最小的“完全括号”方案(结合律顺序)的开销,输出这一整数值。
Example¶
Restriction¶
Time: 3000ms
Memory: 80000KB
Hint¶
数据范围 \(n<2048,K<32\),每个维度的大小 <1000。
本题限制主要在于时间复杂度。
Solution¶
(1)考虑使用动态规划。
(2)张量的第一维是最外层的,越往后的维数对应越里层。
(3)两个 K 维张量相乘时,设有 \(t_1=(m_1,m_2,...,m_{K-2},m_{K-1},m_{K})\) 与 \(t_2=(n_1,n_2,...,n_{K-2},n_{K-1},n_{K})\),首先考虑前 K-2 维,若相同位置两个张量的元素相同,则乘法次数即为这个元素;若该位置一个为 1 另一个为 Dk,那么也就是前一个复制 Dk 后再乘,最后结果相同,都是乘法次数为较大的那个数。
对于后两维,也就是普通的矩阵运算,其中 \(m_K=n_{K-1}\),乘法次数为 \(m_{K-1}*n_K\)。
两个张量相乘之后的新张量形状,对于前 K-2 维,每一位都是原先两个张量在该维度的较大值,后两维为矩阵相乘之后的形状。
(4)使用一个二维向量存储 n 个 K 维张量:std::vector<std::vector<int>> tensor ,第 i 个张量为tensor[i],0<=i<n 。
(5)动态规划的方法是:
创建一个 n*n 的二维向量 std::vector<std::vector> dp 。 dp[i][j],i<=j 代表从第 i 个张量连乘到第 j 个张量时最小的乘法次数。那么最终问题的解就是 dp[0][n-1] 。
初始条件:i==j 的时候两个相同张量不需要相乘,即乘法次数为 0,dp[i][i] = 0 。
状态转移方程: tensor[i] 连乘到 tensor[j] 相乘的最后一步,一定是左右两部分张量各自乘法运算之后的两个新张量相乘的结果,我们将这里的分割点记为 k,也就是最后的最小次数结果,一定是在某个 k 下, tensor[i] 至 tensor[k] 运算后的新张量和 tensor[k+1] 至 tensor[j] 运算后的新张量,这两个新张量做乘法的次数加上已经有的乘法次数是最少的。因此我们可以写出: dp[i][j] = dp[i][k] + dp[k+1][j] + minTimes(i,k,j), for i<=k<j 。这里 minTimes(i,k,j) 即为两个新张量做乘法的次数。
(6)不难发现,上面动态规划的方法最后构成一个 n*n 上三角矩阵,我们递推的顺序是从第 0 列开始到第 n-1 列,每一列从对角线上一个元素开始向上递推,因此最后想要得到 dp[0][n-1] 就不可避免地要求出上三角矩阵的每一个元素,时间复杂度至少为 \(O(n^2)\) 。
整体递推思路是:
for (int j = 1; j < n; j++) {
for (int i = j - 1; i >= 0; i--) {
for (int k = i; k < j; k++) {
// 在这里计算这种分割下的乘法次数
}
// 在这里取最小乘法次数并赋值给 dp[i][j]
dp[i][j] = ...;
}
}
然后对于每一列进行操作时,我们需要知道 tensor[i] 到 tensor[j] 的前 K-2 维每一维度上的最大值,因为这个维度不是这个这个值就是 1,一定会广播复制到这个值,也等于这一维度的乘法次数。对于每一个 j 的循环,i 是从 j-1 开始逐渐减小的,因此可以在第一个循环内创建一个临时张量 std::vector<int> temp(K) ,初始时将 tensor[j] 复制给他,然后在 i 的循环中,i 每向前一步,更新 temp 中的值,使得它的各个维度的大小始终是当前 tensor[i] 到 tensor[j] 的最大值。然后 temp 中前 K-2 维元素连乘,在乘上 tensor[i][K - 2] * tensor[k][K - 1] * tensor[j][K - 1] ,就是我们所说的 minTimes(i,k,j) 。对 k 进行循环,找到最小值即可。
这种方法避免了 i 移动过程中的重复计算,时间效率较高,最后的时间复杂度应为 \(O(K*n^3)\) 。
Code¶
Language: C++
#include <cstdio>
#include <vector>
#include <algorithm>
int main(int argc, const char *argv[])
{
// n个张量,每个都是K维
// n<2048,K<32
int n, K;
scanf("%d%d", &n, &K);
std::vector<std::vector<int>> tensor(n, std::vector<int>(K));
for (int i = 0; i < n; i++)
{
for (int j = 0; j < K; j++)
{
scanf("%d", &tensor[i][j]);
}
}
// dp[i][j]表示从第i个张量到第j个张量运算的最小乘法次数,最后问题的解就是dp[0][n-1]
// i<=j,这是一个上三角矩阵
// 边界条件dp[i][i]=0;
// 状态转移方程dp[i][j]=min(dp[i][k]+dp[k+1][j]+cost(ikj)),i<=k<j
// cost(ikj)为被第k个张量分割的前后两部分相乘的乘法次数
std::vector<std::vector<int>> dp(n, std::vector<int>(n));
for (int i = 0; i < n; i++)
{
dp[i][i] = 0;
}
for (int j = 1; j < n; j++)
{
// 对于第j列,从下向上求解
// 预先计算一部分前K-2维相乘所需要的乘法次数
std::vector<int> temp = tensor[j];
for (int i = j - 1; i >= 0; i--)
{
// 求解dp[i][j]
int result = tensor[i][K - 2] * tensor[j][K - 1];
for (int x = 0; x < K - 2; x++)
{
// i每向前移一位,更新张量各个维度的最大值
temp[x] = std::max(temp[x], tensor[i][x]);
result *= temp[x];
}
int min_times = 0x7fffffff;
for (int k = i; k < j; k++)
{
min_times = std::min(min_times, dp[i][k] + dp[k + 1][j] + result * tensor[k][K - 1]);
}
dp[i][j] = min_times;
}
}
printf("%d", dp[0][n - 1]);
return 0;
}